Project Details
Dataset
Two distinct datasets contribute to the training and evaluation of the grammatical error orrection model.
Approach
The project adopts a Sequence-to-Sequence model as the foundational approach for grammatical error correction. The task is framed as a Natural Language Processing (NLP) problem, specifically in the domain of Natural Language Processing. The chosen approach involves the application of the Sequence-to-Sequence model, where the deep learning model receives an input sequence (incorrect text) and produces an output sequence (corrected text). The project delves into the Sequence-to-Sequence model's intricacies, employing the Sequence-to-Sequence model with attention mechanisms, such as Loung Attention and Monotonic Attention, to enhance the model's performance.
Result
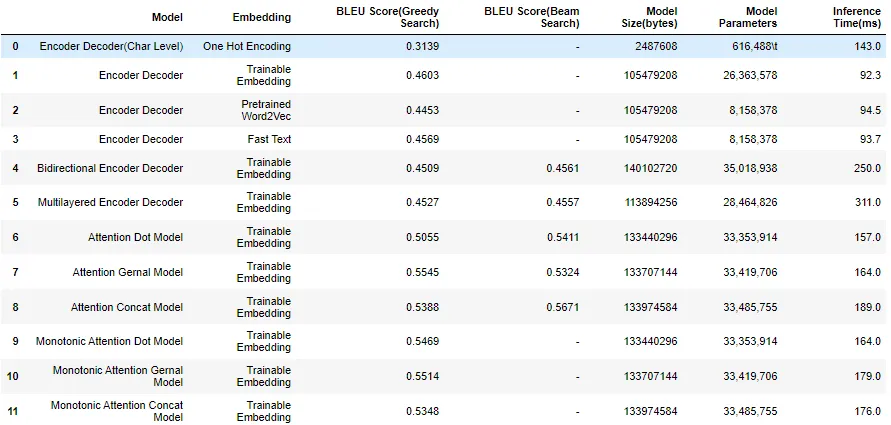
Note: For detailed description check out the blog and Github Repository